Case study - DataMonkey as educational platform
Aug 9th, 2014
A coworker of mine shared a link to DataMonkey, a platform/website to learn basics of data manipulation: Excel spreadsheets and SQL, the language used for database queries in relational databases like MySQL, PostgreSQL and SQLite. During my studies and personal exploration for the best practices in educational systems, I have encountered many that have been quite horrible (like [TRAKLA2](http://www.cse.hut.fi/en/research/SVG/TRAKLA2/ which is used for teaching algorithms and data structures) and many that have a bit better approach (like Codecademy and and ViLLE system for teaching programming).
For me as both as a student and an educator, there are two key factors for making a platform good for educational purposes:
Intuitive User Experience
First one is that the user experience must be so intuitive, easy to follow and pleasant to use that the learner doesn’t have to waste single second thinking about how the system works. Because once you have to focus your attention to things like that, you start losing your motivation and less of your focus goes towards learning the actual subject. The ultimate way to test this, is to see if somebody who understands the subject and can solve problems on say, paper for example, can get through the exercise without problems. From what I have seen, that is also the most difficult part, as UX design often is.
How to help out when learner makes a mistake or doesn’t know what to do
Second, instant and good quality feedback is the bare bone of any education, especially those that don’t involve human interaction with a mentor or teacher. If you keep hitting your head towards the wall because you don’t know what you did wrong, your learning results drop, your motivation drops and you start to generate negative emotions towards the subject. Sometimes it’s just lack of feedback or insufficient feedback but also sometimes the lack of instructions to work with the system.
In programming related platforms, it is quite trivial to separate three things: syntax error, variable error and logical errors. For example, in SQL, syntax error is writing SELCT instead of SELECT, variable error is trying to access a column or table that doesn’t exist, like saying SELECT age, gender, hometown FROM people when the table actually has columns age, gender, city. Especially for SQL, these are quite easy to parse out. And the last one is easy to just test against wanted output.
Case DataMonkey
So, how does DataMonkey rank compared to these requirements? Currently for the SQL, there are two separate paths, with the idea of taking first the Guess SQL path and then the Write SQL yourself path.
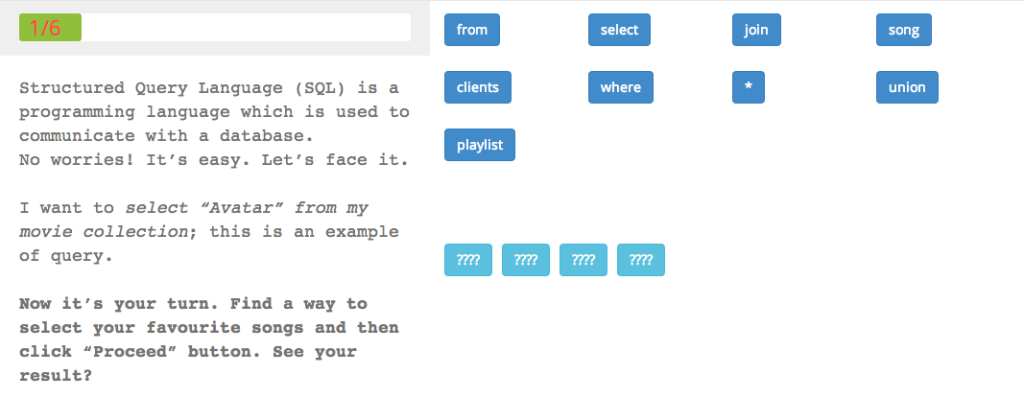
For the Guess SQL, there are three exercises that give you no idea on how to construct SQL. There are some blocks that are already in place and others that you need to click to construct the wanted query. But you can click them in any order and just try to pick out anything that sounds like the plain English query. I can see the intention behind that idea but I fail to see how it helps in any way.
First of all, randomly just selecting tokens from the upper row takes the focus out of the actual thing and doesn’t really aid to construct any larger concepts of SQL or how it works. There is no feedback on selecting the wrong one. The idea of starting slow and not providing any information on SQL has its idea but in my idea, trying to teach something without telling anything about it just doesn’t work. And phrasing things like “Using SQL is as simple as choosing between Option A and Option B—it’s just either this or that! So what do you think is so complicated about it?” isn’t really helping.
The next part is what really bothers me. I understand the project is quite new and there are hopefully a big list of things to improve but currently, I couldn’t really suggest it to any of my freshmen students. In the more serious SQL part where you actually write the SQL yourself, the information given is not sufficient.
Referring things done with programming as magic is something that us engineers and developers joke about but when someone is facing things for the first time, saying that something is magic leaves the wrong impression. It is okay to say something along the lines “Okay, at this point, just believe me to write it like this, we will get back to what is happening later.”
The first actual SELECT statement is not described in any way. It says says to type this in and see that oh, we got everything back. As long as you keep repeating everything the instructions say to the point, you are good to go. But once you make a mistake, things go south. As the following screenshot shows, the student gets no information on WHAT went wrong. Learning from mistakes is the most efficient way of learning but when you have to start guessing, we are on the wrong path.

As I mentioned earlier, syntax, variable and logical errors should be separated with different and more accurate feedback messages. In the above screenshot, there was no column named hometown but it doesn’t even indicate to that direction. Also, sometimes it requires semicolons to terminate commands and sometimes not which can cause really confusing situations.
I really like the idea that DataMonkey is trying to do but the execution is just too way off. Technical cool stuff is irrelevant as long as the important things are off: intuitive user experience and instant feedback. If I would not know anything about SQL and made a mistake somewhere along the line, no matter how subtle, I would be in trouble. I couldn’t even google with the error message since the only one I am getting is platform specific with this platform.
If you happen to be one of the guys working on DataMonkey, please don’t take this too personally, I just got an idea for the blog post when I got the opportunity to look an educational platform with fresh eyes.
If something above resonated with you, let's start a discussion about it! Email me at juhis@hamatti.org and share your thoughts. This year, I want to have more deeper discussions with people from around the world and I'd love if you'd be part of that.