My iterative approach to software development
Sep 6th, 2023

The more I’ve worked with different people in software development, the more I’m fascinated by how different approaches people have to building software. I love seeing other approaches than mine and picking the best parts of those to improve my own workflow.
I’ve been thinking about my approach in contrast with other devs and especially with unspoken expectations from non-developers. By expectations, I mean if someone’s used to a certain way of developers’ work, a new differing way can cause communication issues if not discussed.
To illustrate this blog post, I made these beautiful pictures in Keynote:

That’s the starting point. I’m at the top, there’s a vast brown unknown and somewhere below there, at an unknown depth is the red goal line. My confidence level of if I can reach the red and how fast, varies wildly between features.
Almost always my first goal is just to reach the red line, no matter what. Just to make sure it exists and that I know the direction where to go. What “reaching the red line” means, is usually a quick-and-dirty prototype that achieves one main part of the functionality.

So the first iteration is very narrow and to the point. It helps with two things: I can quickly see where the goal is, can I reach it and I can start demoing it with interested people to see if the red line was correct one and where to go from there.
In my experience, this is quite common in agile development at least amongst the devs I’ve worked with. You start with something and then iterate to make it better.

Once I then start the next iteration, I essentially break what used to work. While the next iteration is on-going, I don’t usually have a way to demo the progress anymore. I can always go back to the end of first iteration and demo that but the progress from there onwards is not linear, it’s rather wibbly-wobbly. Now that I know and am confident I can reach the goal, I’m confident I don’t need to be able to reach it all the time and I can start building again from scratch (or almost from scratch), this time with better supports. These supports usually mean better code, better infrastructure, tests and so on.
It’s going backwards in progress to make it easier to end with a better result.
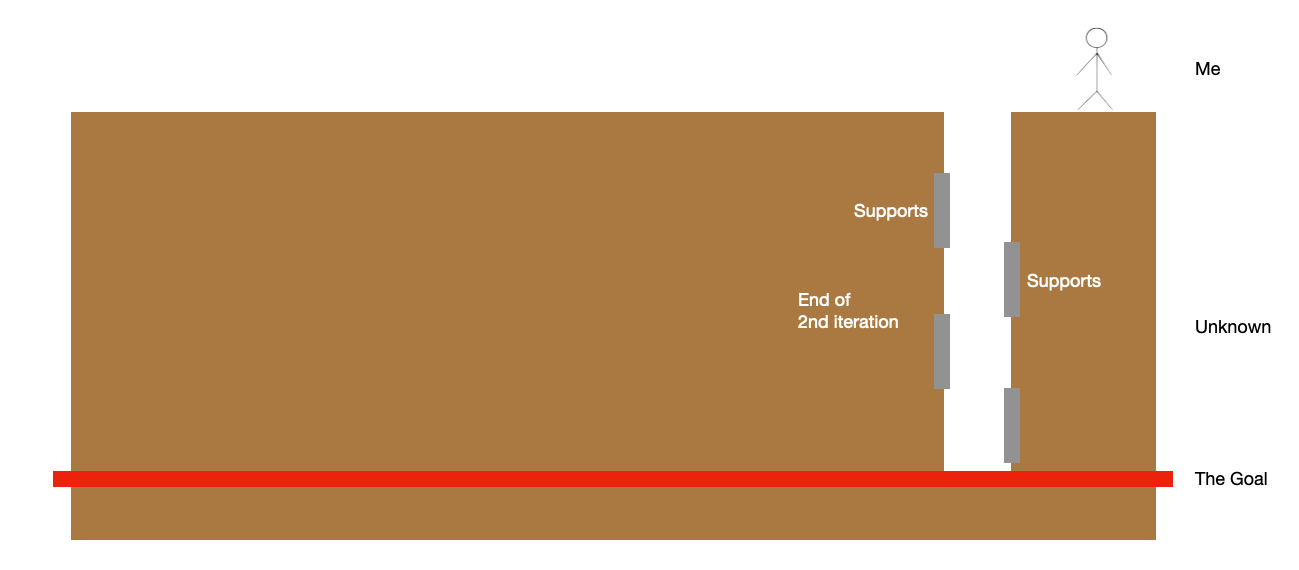
At the end of the 2nd iteration, I have once again reached the red goal line but this time there’s more there. Maybe I’m connecting the improved prototype to some existing production-level integration and started prototyping on that end too.
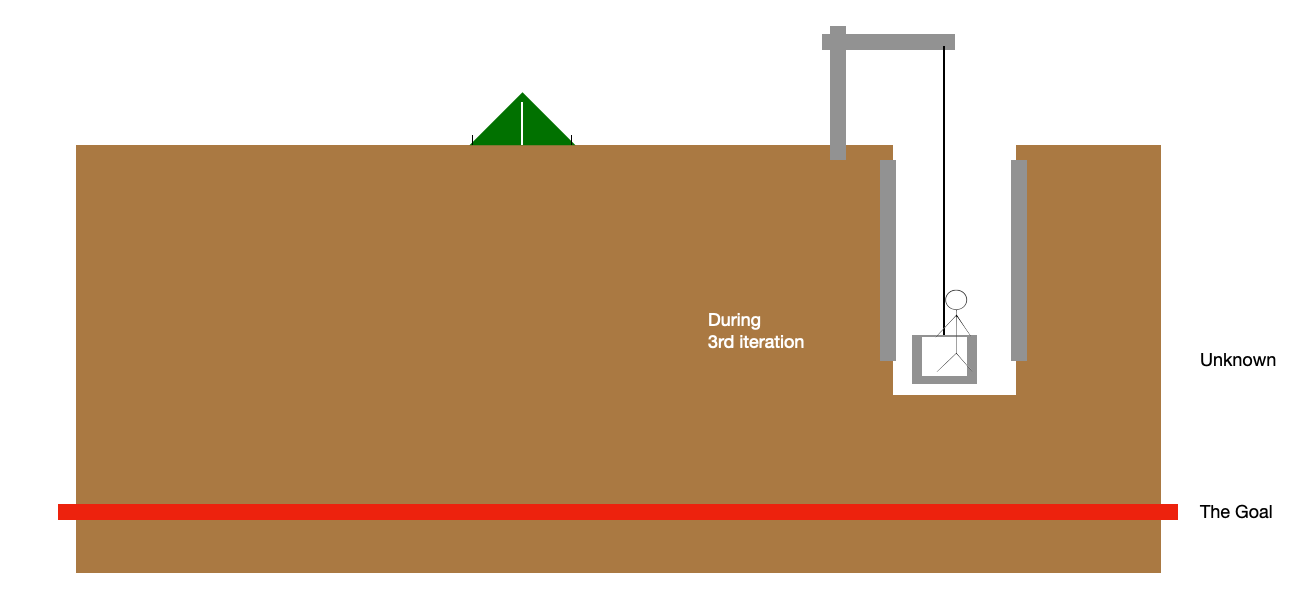
And then I jump on to the next iteration, once again losing sight of the goal. By writing something once and then discarding it rather than trying to change it in-place, I usually come out with way better architected solutions with cleaner and more understandable code and better user flows.
Every time I’ve reached the goal, my map of what’s on the path gets more detailed and clearer, making it easier to craft better paths towards it. But once again, while I’m crafting the new path, I might not have anything that works until I reach the goal line again.
And quite often, the length of an iteration ever so slightly increases during these because I’m putting more care and effort into them.
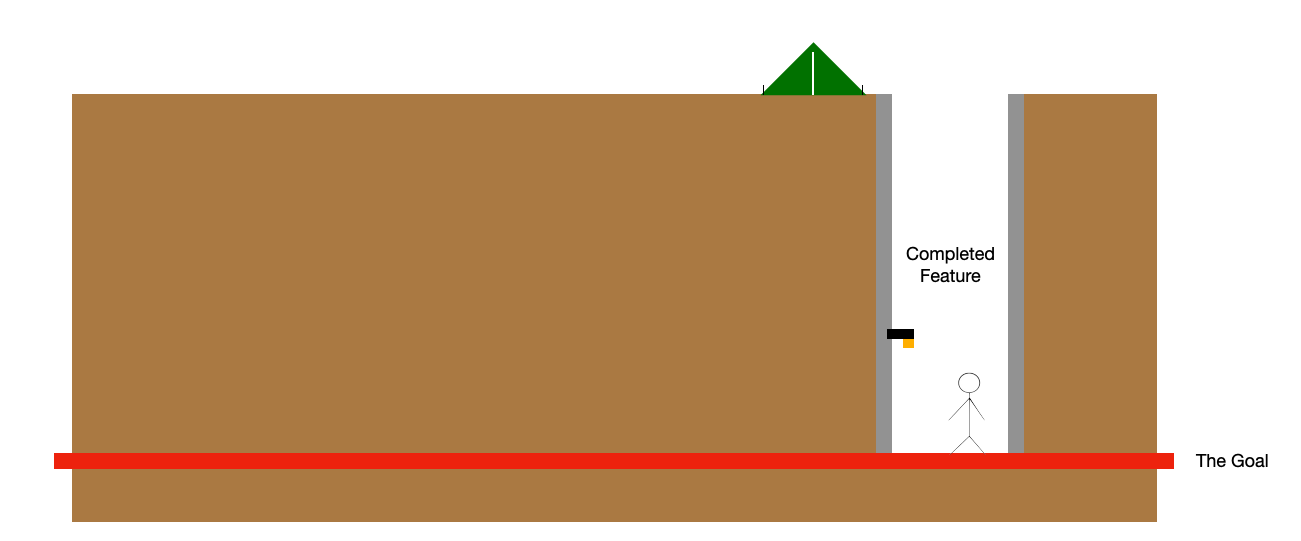
This is why I like the lean and iterative approach. I’ll be honest with you: it’s very rare that at the beginning of a feature I’m confident enough that I can build it right on the first try. So I very rarely try to make it perfect from the start.
Usually this process from first iteration to “completed” (is anything ever completed in software world?) lives within a pull request cycle and can be done all within a day with multiple iterations if a feature is small.
But 99% of the time, when I start developing something, the first version is not code I’d ever push to production. I may create a pull request on it so I can gain feedback on the idea on technical level early on but there are always multiple rounds of iteration that I go through as I craft solutions.
If something above resonated with you, let's start a discussion about it! Email me at juhamattisantala at gmail dot com and share your thoughts. This year, I want to have more deeper discussions with people from around the world and I'd love if you'd be part of that.